AI / ML
2019. 06. 19 (Wed)
AI, ML을 배우는 이유?
마케팅(광고), 헬스케어, 이미지 분석등 기존 컴퓨터 연산으로 할 수 없는 기능 구현
자연어 처리가 가능?
카테고리별 인식이 아닌 자연어 기반으로 문장을 이해
무엇을 파악?
알고리즘 작동 방식 파악 보다
데이터를 어떻게 사용할지, 무엇을 만들지 파악
자연어 처리 기능 챗봇
자연어 처리 기능 구현
텍스트 데이터 전 처리
텍스트 tokenization
텍스트 vectorization
텍스트 embedding
Deep Neural Network 구조 파악 및 챗봇 구현
트레이닝 데이터 전 처리
Language Model을 이용한 챗봇 모델 구현
추가: BERT 모델을 사용?
구조
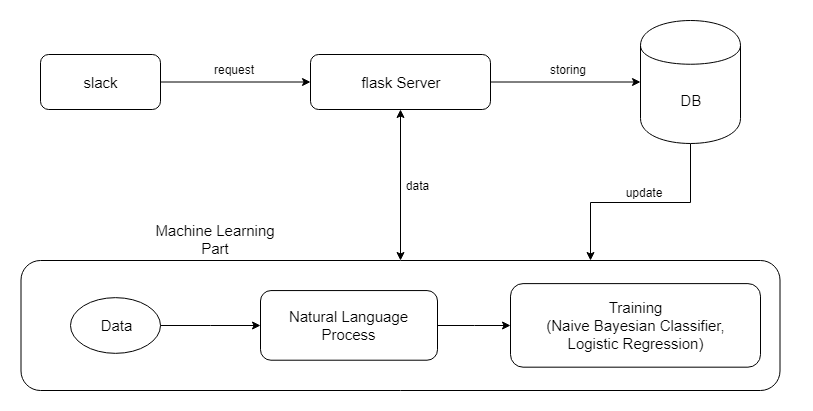
Machine Learning
CS?
인간이 알고리즘을 기계한테 알려주어 input에 대한 output을 구한다.
ML?
최소한의 모델과 많은 데이터를 주고 기계가 알고리즘을 학습한다. 이후 새로운 input에 대해 output을 예측.
DL?
ML에 사용하는 모델의 종류가 많은데 인공신경망모델(인간의 학습 모델)을 사용한 머신러닝
현업에서는?
얼마나 효율성을 높이고 최적화를 하느냐가 주된 이슈.
1. 머신러닝 분류
학습 데이터에 레이블이 있는 경우와 그렇지 않은 경우에 따라 지도, 비지도 학습으로 구분
지도 학습
학습 데이터 레이블을 갖고 학습.
분류classifier(KNN, SVM, Decision Tree, Logistic Regression): 데이터가 discrete
예측(Liner Regression): 데이터가 continuous
비지도 학습
학습 데이터 레이블 없이 학습
기계가 데이터를 어떤 사람이 판단하는 기준에 따라 군집화(clustering)
정확도보다는 경향성 패턴을 예측
이상탐지(Anomaly detection): 데이터샘플에서 패턴에서 벗어난 데이터를 이상값이라고 한다. 이를 탐지하고 예측 군집화에 반영
시각화(visualization): 데이터의 특성을 시각화 하여 패턴 연구
자원축소(dimensionality reduction): 상관관계가 있는 여러 특성을 하나로 합침
강화 학습
어떤 환경안에서 에이전트 현재의 상태를 인식하여, 선택 가능한 행동중 보상을 최대화하는 행동을 학습
게임환경에서 많이 사용
- 게임환경 안에서
- 마리오의 현재 상태를 인식하고
- 보상에 따라 선택하는 핵동을 학습
보상을 어떻게 주냐에 따라 행동이 결정된다.
issue
과정합(overfitting): 너무 학습데이터에 지나치게 맞추다 보면 일반화 성능보다 떨어지는 학습 모델을 얻는 경우가 있다.
따라서 training set에만 너무 맞추기 보다. test set의 accuracy까지 고려하여 학습하는 것이 바람직
자연어 처리
자연어를 컴퓨터에서 분석하고 처리
자연어처리의 목적
대량의 자연어 데이터 처리
컴퓨터에 자연어를 이해시키는 시스템
AI, ML, DL에 사용
1. 자연어 전 처리 과정
Noise canceling: 스펠링체크, 띄어쓰기 오류 교정
Tokenizing: 문장을 토큰으로 나눈다. 어절, 단어등으로 목적에 따라 다르게 정의
Part-of-Speech tagging: 토큰의 품사 판별
Filtering: 불필요한 단어 제거
Term vector representation: (문서, 단어)행령에서 각 단어의 중요도를 조절
Transformation: TF-IDF 방식등으로 term-vector 변환
딥러닝
인공 신경망 모델을 기반으로 하는 기계학습 기술
Perceptron
인간 두뇌와 유사한 동작
각 input에 대한 가중치를 적용하여 output 산출
ex) y = w1*x1 + w2*x2 + B
- w = 가중치
- x = input
- B = Bias
그렇다면 이를 평면에서 선으로 구현할 경우, 논리연산이 가능해진다.
근데 XOR연산이 불가
Multi Perceptron
다층 퍼셉트론으로 XOR 연산 가능
문제점?
비선형이 불가
다층에서 가중치 적용이 어렵다